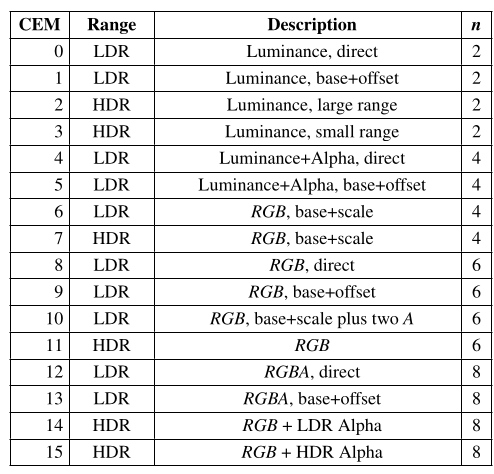
It has been quite a while since the last post where I discussed the binding model shenanigans of D3D12, and as promised, it’s time to look at AMD code-gen for various API patterns we find in D3D12 when translated to Vulkan and the ACO compiler in RADV.
At a fundamental level, the AMD ISAs haven’t changed all that much since the GCN 1.0 days, for good reason. Arguably, it’s still the cleanest and most flexible descriptor model of any GPU architecture and it’s a very useful architecture to understand at a low level.
As discussed last time, the same DXIL code can translate to many different code patterns in SPIR-V. The Root Signature object in D3D12 not only concerns itself with mapping binding points, but also controls the physical implementation of how resources are accessed. This means we have to deal with all of this junk in dxil-spirv somehow.
Using Fossilize as our cross-vendor RGA – fossilize-synth and fossilize-disasm
For the ISA experiments we conduct here, we’ll use fossilize-synth and fossilize-disasm. These CLI tools are part of the Fossilize project and they can be used to conduct ISA experiments like these quite handily. Unlike RGA, fossilize-synth can automatically generate a compatible VkPipelineLayout, VkRenderPass and PSO state for given shaders and record this as a Fossilize archive. We can then replay it with fossilize-disasm, target ISA output and output ISA on any driver that supports VK_KHR_pipeline_executable_properties fully.
$ dxil-spirv --output test.spv test.dxil
$ fossilize-synth --output test.foz --comp test.spv
Fossilize INFO: Successfully synthesized a FOZ archive to /tmp/test.foz.
$ fossilize-disasm --target isa --output /tmp test.foz
Fossilize INFO: Dumping disassembly to: /tmp/888210fc26602b56.main.a2d87808e64b9164.comp
How many ways can we implement Constant Buffer View?
Welcome to hell.
Constant buffers can be implemented a million different ways, so let’s have a look at what we generate for an RDNA2 chip and some alternatives we have to use for other vendors. As a test shader, we start with this HLSL compute shader:
cbuffer Cbuf : register(b0)
{
uint4 v;
};
RWStructuredBuffer<uint4> RW : register(u0);
[numthreads(64, 1, 1)]
void main(uint thr : SV_DispatchThreadID)
{
RW[thr] *= v;
}
1. Root constant – Global Root Signature
Root constants translate naturally to push constants in Vulkan. The Vulkan GLSL representation of dxil-spirv output is:
#version 450
layout(local_size_x = 64, local_size_y = 1, local_size_z = 1) in;
layout(set = 0, binding = 0, std430) buffer SSBO
{
uvec4 _m0[];
} _13;
layout(push_constant, std430) uniform RootConstants
{
uint _m0;
uint _m1;
uint _m2;
uint _m3;
} registers;
void main()
{
uvec4 _33 = uvec4(registers._m0, registers._m1,
registers._m2, registers._m3);
_13._m0[gl_GlobalInvocationID.x] =
uvec4(_13._m0[gl_GlobalInvocationID.x].x * _33.x,
_13._m0[gl_GlobalInvocationID.x].y * _33.y,
_13._m0[gl_GlobalInvocationID.x].z * _33.z,
_13._m0[gl_GlobalInvocationID.x].w * _33.w);
}
s_mov_b32 s0, s3
s_movk_i32 s3, 0x8000
s_load_dwordx4 s[8:11], s[2:3], 0x0
v_lshl_add_u32 v0, s7, 6, v0
v_lshlrev_b32_e32 v0, 4, v0
s_waitcnt lgkmcnt(0)
// Interesting work begins here
buffer_load_dwordx4 v[4:7], v0, s[8:11], 0 offen
s_waitcnt vmcnt(0)
v_mul_lo_u32 v8, v4, s0
v_mul_lo_u32 v9, v5, s4
v_mul_lo_u32 v10, v6, s5
v_mul_lo_u32 v11, v7, s6
buffer_store_dwordx4 v[8:11], v0, s[8:11], 0 offen
s_endpgm
The first thing to understand about GCN and RDNA is the execution model. On basically any modern GPU, threads are executed in groups. “Waves”, “warps” and “subgroups” are all names for the same thing. “Wave” is the preferred AMD naming, so we’ll use that. An instruction here is either a wide vector instruction or a scalar instruction. Scalar instructions run once in the small scalar unit, and vector instructions run wide.
Scalar registers and vector registers are similar here. v registers are per-lane (called VGPR), and scalar s registers are stored once per wave (called SGPR). To translate this to x86-speak, SGPRs are normal registers like rax, rbx, etc. VGPRs would be AVX-2048 monsters, crunching 64 operations in parallel.
A critical performance consideration when targeting AMD is “scalarization”. When data is the same across a wave, we can place it in scalar registers. This keeps register pressure down. We have scalar registers in abundance, but using too many vector registers leads to poor occupancy. Shifting vector registers to scalar registers is therefore a sound strategy.
With this in mind, let’s look at the interesting bit:
s_mov_b32 s0, s3
v_mul_lo_u32 v8, v4, s0
v_mul_lo_u32 v9, v5, s4
v_mul_lo_u32 v10, v6, s5
v_mul_lo_u32 v11, v7, s6
This is the meat of the work. When execution is begun, the root constants are already placed in s3, s4, s5 and s6. This is ideal. No need to load anything explicitly. This is possible because of “User SGPRs”. There is however, a strict limit to how much “User SGPR” data we can hold. If we have too many constants, the driver is forced to insert indirection.
For example, consider:
cbuffer Cbuf : register(b0)
{
uint4 v0;
uint4 v1;
uint4 v2;
uint4 v3;
};
RWStructuredBuffer<uint4> RW : register(u0);
[numthreads(64, 1, 1)]
void main(uint thr : SV_DispatchThreadID)
{
RW[thr] *= v0;
RW[thr] *= v1;
RW[thr] *= v2;
RW[thr] *= v3;
}
Now we end up with:
s_mov_b32 s0, s3
s_movk_i32 s1, 0x8000
s_clause 0x1
s_load_dwordx4 s[16:19], s[0:1], 0x20
s_load_dwordx4 s[20:23], s[0:1], 0x30
s_movk_i32 s3, 0x8000
s_load_dwordx4 s[0:3], s[2:3], 0x0
v_lshl_add_u32 v0, s12, 6, v0
v_lshlrev_b32_e32 v0, 4, v0
s_waitcnt lgkmcnt(0)
buffer_load_dwordx4 v[4:7], v0, s[0:3], 0 offen
s_waitcnt vmcnt(0)
v_mul_lo_u32 v4, v4, s4
v_mul_lo_u32 v5, v5, s5
v_mul_lo_u32 v6, v6, s6
v_mul_lo_u32 v1, v7, s7
v_mul_lo_u32 v4, v4, s8
v_mul_lo_u32 v5, v5, s9
v_mul_lo_u32 v2, v6, s10
v_mul_lo_u32 v1, v1, s11
v_mul_lo_u32 v3, v4, s16
v_mul_lo_u32 v4, v5, s17
v_mul_lo_u32 v2, v2, s18
v_mul_lo_u32 v1, v1, s19
v_mul_lo_u32 v8, v3, s20
v_mul_lo_u32 v9, v4, s21
v_mul_lo_u32 v10, v2, s22
v_mul_lo_u32 v11, v1, s23
buffer_store_dwordx4 v[8:11], v0, s[0:3], 0 offen
s_endpgm
Some of the root constants were promoted to User SGPR, but some were not and the driver had to spill those to memory somewhere, and load them.
s_load_dwordx4 s[16:19], s[0:1], 0x20
s_load_dwordx4 s[20:23], s[0:1], 0x30
Since the constants are the same for all threads, we can load them directly into SGPRs instead of doing silly broadcasts.
Scalar loads on AMD have special properties. First, they target the constant cache (K$) instead of normal data caches. The K$ is not coherent with the data caches, so we can use the K$ if the address to load is scalar and we know that we do not need to alias with other writes. SSBO loads can actually use this path too if these constraints are met, which will come in handy in the next section.
2. Root descriptor – Global Root Signature – Buffer Device Address (BDA)
Root descriptors in D3D12 are designed to be raw pointers to data and they take up 64 bits in the root signature. It is up to the implementation to figure out what to do about the raw pointer, and in vkd3d-proton we prefer to translate this to push constant BDA on AMD.
Let’s first try with dynamically uniform address:
cbuffer Cbuf : register(b0)
{
uint4 v[8];
};
RWStructuredBuffer<uint4> RW : register(u0);
[numthreads(64, 1, 1)]
void main(uint thr : SV_DispatchThreadID, uint wg : SV_GroupID)
{
RW[thr] *= v[wg];
}
The output Vulkan GLSL is … funky:
#version 450
#extension GL_EXT_buffer_reference : require
#extension GL_EXT_buffer_reference_uvec2 : require
layout(local_size_x = 64, local_size_y = 1, local_size_z = 1) in;
struct AddCarry
{
uint _m0;
uint _m1;
};
layout(buffer_reference) buffer PhysicalPointerUint4NonWrite;
layout(buffer_reference, buffer_reference_align = 16, std430)
readonly buffer PhysicalPointerUint4NonWrite
{
uvec4 value;
};
layout(set = 0, binding = 0, std430) buffer SSBO
{
uvec4 _m0[];
} _14;
layout(push_constant, std430) uniform RootConstants
{
uvec2 _m0;
} registers;
void main()
{
AddCarry _33;
// Pointer arithmetic is fun >:|
_33._m0 = uaddCarry(registers._m0.x, gl_WorkGroupID.x * 16u, _33._m1);
PhysicalPointerUint4NonWrite _40 =
PhysicalPointerUint4NonWrite(uvec2(_33._m0, registers._m0.y +
_33._m1));
_14._m0[gl_GlobalInvocationID.x] =
uvec4(_14._m0[gl_GlobalInvocationID.x].x * _40.value.x,
_14._m0[gl_GlobalInvocationID.x].y * _40.value.y,
_14._m0[gl_GlobalInvocationID.x].z * _40.value.z,
_14._m0[gl_GlobalInvocationID.x].w * _40.value.w);
}
In the BDA path of dxil-spirv, we encode the BDA in push constants, perform address calculation, cast that to a pointer and load. The critical part here is NonWritable decoration. This signals the compiler that the memory region can be assumed to not have been written to, even with aliasing in this shader module. This is subtly different from C const. Const can still observe aliasing through other pointer, but not in SPIR-V. This allows ACO to generate ideal code even from raw pointers:
s_mov_b32 s0, s3 // S[3:4] holds BDA
s_lshl4_add_u32 s0, s5, s0 // S5 holds SV_GroupID.x here
s_add_u32 s1, s4, src_scc // Handle carry for 64-bit + 32-bit
s_load_dwordx4 s[0:3], s[0:1], 0x0 // Scalar load from pointer
s_waitcnt vmcnt(0) lgkmcnt(0)
v_mul_lo_u32 v8, v4, s0
v_mul_lo_u32 v9, v5, s1
v_mul_lo_u32 v10, v6, s2
v_mul_lo_u32 v11, v7, s3
Nice. If we remove the NonWritable from SPIR-V assembly we get the depressing vector load instead, because compiler can no longer prove there is no potential aliased write (we’re doing pointer arithmetic after all), so we have to do it in the vector unit instead:
global_load_dwordx4 v[4:7], v[2:3], off
Of course, if the shader is loading uniforms with varying offset we also need vector loads, e.g.:
cbuffer Cbuf : register(b0)
{
uint4 v[8];
};
RWStructuredBuffer<uint4> RW : register(u0);
[numthreads(64, 1, 1)]
void main(uint thr : SV_DispatchThreadID, uint wg : SV_GroupID)
{
RW[thr] *= v[thr & 7];
}
v_lshl_add_u32 v0, s5, 6, v0
v_and_b32_e32 v1, 7, v0
v_add_nc_u32_e32 v2, s0, v1 // Vectorized 64-bit + 32-bit
v_add_co_u32 v1, s[0:1], s0, v1
v_add_co_ci_u32_e64 v3, vcc, 0, s4, s[0:1]
global_load_dwordx4 v[4:7], v[2:3], off
The code-gen isn’t perfect here, but it accomplishes what we need for Root CBV. I am considering rewriting the pointer arithmetic for CBV to just use access chains instead, but that’s for another time …
(The existing codegen was designed for Root SRV / UAV which can do unaligned loads and stores in weird ways, and it is easier to do it this way with pointer arithmetic ._.)
(The reason we use uvec2 here is quirky. At the time, ACO only promoted 32-bit uints to User SGPRs, not 64-bit.)
3. Root constant – Global Root Signature – INLINE_UNIFORM_BUFFER workaround
If the driver does not support 256 byte push constants, we might be forced to fall back to inline UBO blocks instead of using push constants for massive root signatures. The generated code would look more or less the same as the BDA scenario shown above. Inline UBO on AMD is implemented in a way where the UBO data is stored at an offset from descriptor set pointer.
Now that BDA is widespread we might want to nuke this workaround and instead implement the workaround as a push constant BDA to memory we allocate ourselves. This removes the need to deal with annoying descriptor sets just to handle this case.
4. Root descriptor – Global Root Signature – Plain Descriptor
Push descriptors aren’t very special on AMD, so it gets lumped in with the others here. It just means the driver needs to allocate descriptor memory behind the scenes, which means extra CPU overhead. Descriptor paths on AMD have two indirections. This is why we prefer using BDA. For the example above with dynamically uniform address:
RW[thr] *= v[wg];
s_movk_i32 s3, 0x8000
s_load_dwordx4 s[8:11], s[2:3], 0x0
s_buffer_load_dwordx4 s[0:3], s[8:11], s0
In SGPRs, pointers to descriptor sets can be pushed. Descriptor memory lives in a 4 GB virtual memory range, so RADV only needs to push a 32-bit pointer to store a descriptor set and the upper half is synthesized from a constant. From here, we load a UBO descriptor. With the descriptor in SGPR, we load the actual UBO data.
A thing to note here is how trivial it is to extend this to bindless / descriptor indexing. Just adjust the offset when loading the UBO descriptor and that’s all we need. No magic involved, descriptors are just memory in this model.
This path is preferred on NVIDIA however. Push descriptors are more “magical” there and the BDA path is very slow compared to that. 🙁
5. Root table – Global Root Signature
In root tables, we need to tap into descriptor indexing. The table parameter in D3D12 works like an offset into the ID3D12DescriptorHeap. This offset is placed in push constants, which we then use to offset into the heap. E.g. given this HLSL shader:
struct C { uint4 value; };
ConstantBuffer<C> CBVs[] : register(b10);
RWStructuredBuffer<uint4> RW : register(u1);
[numthreads(64, 1, 1)]
void main(uint thr : SV_DispatchThreadID, uint wg : SV_GroupID)
{
RW[thr] *= CBVs[wg].value;
}
we end up with Vulkan GLSL looking like:
#version 450
#extension GL_EXT_buffer_reference : require
#extension GL_EXT_nonuniform_qualifier : require
layout(local_size_x = 64, local_size_y = 1, local_size_z = 1) in;
// If VK_VALVE_mutable_descriptor_type, SSBO and BindlessCBV can share
// same descriptor binding.
layout(set = 4, binding = 0, std430) buffer SSBO
{
uvec4 _m0[];
} _14[];
layout(set = 5, binding = 0, std140) uniform BindlessCBV
{
vec4 _m0[4096];
} _22[];
layout(push_constant, std430) uniform RootConstants
{
uint _m0;
uint _m1;
uint _m2;
uint _m3;
uint _m4;
uint _m5;
uint _m6;
uint _m7;
} registers;
void main()
{
uint _29 = registers._m4 + 1u;
uvec4 _52 = floatBitsToUint(_22[registers._m5 +
(gl_WorkGroupID.x + 10u)]._m0[0u]);
_14[_29]._m0[gl_GlobalInvocationID.x] =
uvec4(_14[_29]._m0[gl_GlobalInvocationID.x].x * _52.x,
_14[_29]._m0[gl_GlobalInvocationID.x].y * _52.y,
_14[_29]._m0[gl_GlobalInvocationID.x].z * _52.z,
_14[_29]._m0[gl_GlobalInvocationID.x].w * _52.w);
}
The ISA looks like:
v_lshl_add_u32 v0, s6, 6, v0 // Compute DispatchThreadID.x
s_add_u32 s0, s6, s5 // Add GroupID.x + root table offset
s_lshl_b32 s0, s0, 4 // sizeof(UBO) == 16
s_mov_b32 s6, s3 // Build pointer to set
s_movk_i32 s7, 0x8000
// Load descriptor by index.
// Missing constant offset here. LLVM disassembler bug I think ...
// Raw opcode is f4080203 000000a0
s_load_dwordx4 s[8:11], s[6:7], s0
...
s_buffer_load_dwordx4 s[4:7], s[8:11], 0x0
Fundamentally, this is no different from legacy descriptors. The offset is just no longer constant.
6. Root table – Global Root Signature – NonUniformResourceIndex
Adding more spice, we’ll make the resource index not uniform. Descriptors on AMD have to live in scalar registers for good reasons, so for this case we will see a common pattern in advanced compute, waterfall loops.
struct C { uint4 value; };
ConstantBuffer<C> CBVs[] : register(b10);
RWStructuredBuffer<uint4> RW : register(u1);
[numthreads(64, 1, 1)]
void main(uint thr : SV_DispatchThreadID, uint wg : SV_GroupID)
{
RW[thr] *= CBVs[NonUniformResourceIndex(thr % 3)].value;
}
This just translates to nonuniformEXT() in Vulkan GLSL, so there’s nothing interesting to see here, but the ISA is unrecognizable.
BB0:
s_lshl_b32 s4, s4, 4
s_mov_b32 s0, s3
s_movk_i32 s3, 0x8000
s_load_dwordx4 s[8:11], s[2:3], s4
v_lshl_add_u32 v0, s6, 6, v0
v_mul_hi_u32 v1, v0, 0xaaaaaaab
v_lshrrev_b32_e32 v1, 1, v1
v_lshl_add_u32 v1, v1, 1, v1
v_sub_nc_u32_e32 v1, v0, v1
v_lshlrev_b32_e32 v0, 4, v0
s_waitcnt lgkmcnt(0)
buffer_load_dwordx4 v[4:7], v0, s[8:11], 0 offen
v_add_lshl_u32 v1, s5, v1, 4
v_add_nc_u32_e32 v1, 0xa0, v1
// REGION OF INTEREST - BEGIN
s_mov_b64 s[2:3], exec
BB1:
v_readfirstlane_b32 s1, v1
v_cmp_eq_i32_e32 vcc, s1, v1
s_and_saveexec_b64 s[4:5], vcc
s_cbranch_execz BB9
BB2:
s_mov_b32 s6, s0
s_movk_i32 s7, 0x8000
s_load_dwordx4 s[12:15], s[6:7], s1
s_waitcnt lgkmcnt(0)
s_buffer_load_dwordx4 s[12:15], s[12:15], 0x0
s_waitcnt lgkmcnt(0)
v_mov_b32_e32 v1, s15
v_mov_b32_e32 v2, s14
v_mov_b32_e32 v3, s13
v_mov_b32_e32 v8, s12
s_andn2_b64 s[4:5], s[4:5], exec
s_cbranch_scc0 BB10
BB9:
s_mov_b64 exec, s[4:5]
s_branch BB1
// REGION OF INTEREST - END
BB10:
s_mov_b64 exec, s[2:3]
s_waitcnt vmcnt(0)
// Actually do the math.
v_mul_lo_u32 v8, v4, v8
v_mul_lo_u32 v9, v5, v3
v_mul_lo_u32 v10, v6, v2
v_mul_lo_u32 v11, v7, v1
// Store result.
buffer_store_dwordx4 v[8:11], v0, s[8:11], 0 offen
s_endpgm
This is … a bit more complicated, but now we get to study the corner stone of SIMD-style control flow – execution masking – in more detail.
The principle behind waterfall loops is that we need to partition a wave into sets which have the same value. The more divergence in a wave, the more loop iterations are needed. For sake of simplicity in the example below, we can assume a wave size of 8 (it’s actually 64 here).
The descriptor indices could be something like: index = { 0, 1, 2, 0, 1, 2, 0, 1 }. The waterfall loop looks like this in pseudo-code:
uint dynamic_index = thr % 3;
for (;;)
{
uint index = subgroupBroadcastFirst(dynamic_index);
if (index == dynamic_index)
{
desc = load_descriptor(index);
data = load_data_from_descriptor(desc);
break; // Stay tuned for structurization blogs, harharharhar :V
}
}
In the first iteration, we look at our active thread mask (0xff), find the first bit set, which is 0. Lane 0 holds the value 0.
v_readfirstlane_b32 s1, v1 // A compute enthusiast's best friend!
Any other lane with the same value can go ahead, so lane 0, 3 and 6 will enter the branch.
v_cmp_eq_i32_e32 vcc, s1, v1
s_and_saveexec_b64 s[4:5], vcc
The index is now known to be constant over the wave, so we can now load the UBO descriptor and data, but the result must be moved to vector registers since we don’t load from wave uniform resource indices here:
s_buffer_load_dwordx4 s[12:15], s[12:15], 0x0
// The v_mov is only executed for active lanes.
v_mov_b32_e32 v1, s15
v_mov_b32_e32 v2, s14
v_mov_b32_e32 v3, s13
v_mov_b32_e32 v8, s12
The lanes which participate are now masked out, and the exec mask would be 0xff & ~(0x01 | 0x08 | 0x40). In the next iteration, we look at the first active lane, which has the value 1, and so we roll on until all unique values have been processed. Neat!
s_cbranch_scc0 BB10 // Keep going until we've masked out all exec bits.
7. ResourceDescriptorHeap – SM 6.6
This is trivially similar to the root table case, so I’ll omit ISA here. The main problem is DXIL having to define a completely different set of opcodes for SM 6.6, but that’s another story <_<. Overall it is simpler. Root tables are translated to SM 6.6 automatically in dxil-spirv after all.
struct C { uint4 value; };
RWStructuredBuffer<uint4> RW : register(u0, space1);
[numthreads(64, 1, 1)]
void main(uint thr : SV_DispatchThreadID, uint wg : SV_GroupID)
{
ConstantBuffer<C> CBV = ResourceDescriptorHeap[wg];
RW[thr] *= CBV.value;
}
#version 450
#extension GL_EXT_nonuniform_qualifier : require
layout(local_size_x = 64, local_size_y = 1, local_size_z = 1) in;
layout(set = 0, binding = 0, std140) uniform BindlessCBV
{
vec4 _m0[4096];
} _13[];
layout(set = 1, binding = 0, std430) buffer SSBO
{
uvec4 _m0[];
} _18;
void main()
{
uvec4 _34 = floatBitsToUint(_13[gl_WorkGroupID.x]._m0[0u]);
_18._m0[gl_GlobalInvocationID.x] =
uvec4(_18._m0[gl_GlobalInvocationID.x].x * _34.x,
_18._m0[gl_GlobalInvocationID.x].y * _34.y,
_18._m0[gl_GlobalInvocationID.x].z * _34.z,
_18._m0[gl_GlobalInvocationID.x].w * _34.w);
}
8. Root table / ResourceDescriptorHeap – Pascal workaround
On older NVIDIA hardware, we cannot use bindless UBO at all, as hardware does not support it. The workaround is to use bindless SSBO instead, with hilarious performance loss as a result :’)
9. Root constant – Local Root Signature
Local root signatures are an abomination. There is no fossilize-synth support for RTPSOs at this time, so I’ll resort to just showing the Vulkan GLSL equivalent. In Vulkan, the shader record block works just like an SSBO, but D3D12 insists on the abstracted model of root signatures, so when emitting code we need to consider if a resource belongs to the local root signature or global root signature.
struct CBVData { float4 v; };
ConstantBuffer<CBVData> SBTRootConstant : register(b0, space15);
ConstantBuffer<CBVData> SBTRootConstant2 : register(b1, space15);
struct Payload
{
float4 color;
int index;
};
[shader("miss")]
void RayMiss(inout Payload payload)
{
payload.color = SBTRootConstant.v;
payload.color += SBTRootConstant2.v;
}
#version 460
#extension GL_EXT_ray_tracing : require
#extension GL_EXT_buffer_reference : require
#extension GL_EXT_nonuniform_qualifier : require
struct _19
{
vec4 _m0;
uint _m1;
};
layout(shaderRecordEXT, std430) buffer SBTBlock
{
uint _m0[5];
uint _m1[6];
// ... Local root signature parameters.
// The exact binary layout is implied by the root signature
// parameter order.
} SBT;
layout(push_constant, std430) uniform RootConstants
{
uint _m0;
// ... Global root signature parameters
} registers;
layout(location = 0) rayPayloadInEXT _19 payload;
vec4 _67;
void main()
{
vec4 _41 = uintBitsToFloat(uvec4(SBT._m0[0u], SBT._m0[1u], SBT._m0[2u], SBT._m0[3u]));
vec4 _57 = uintBitsToFloat(uvec4(SBT._m1[0u], SBT._m1[1u], SBT._m1[2u], SBT._m1[3u]));
// Ah, yes, the classic LLVM composite insert pattern from undef vector.
// You thought DXIL didn't support composites? Think again! :D
vec4 _66 = _67;
_66.x = _41.x + _57.x;
vec4 _68 = _66;
_68.y = _41.y + _57.y;
vec4 _69 = _68;
_69.z = _41.z + _57.z;
vec4 _70 = _69;
_70.w = _41.w + _57.w;
payload._m0 = _70;
}
10. Root descriptor – Local Root Signature
Unlike the global root signature, we are forced to use BDA here. It is physically impossible to translate this to push descriptors since we have no chance to observe this pointer on CPU side. The GPU can generate this pointer on its own. It’s a bit hilarious that we can use raw pointers like this on D3D12 since forever, but we cannot actually use the pointer directly in the shader 😐
The SPIR-V is similar to global root signature, we just have to source the BDA from record block instead.
AddCarry _31;
_31._m0 = uaddCarry(SBT._m6.x, 0u * 16u, _31._m1);
PhysicalPointerFloat4NonWrite _38 =
PhysicalPointerFloat4NonWrite(uvec2(_31._m0, SBT._m6.y + _31._m1));
vec4 _57 = _58;
_57.x = payload._m0.x + _38.value.x;
vec4 _59 = _57;
_59.y = payload._m0.y + _38.value.y;
vec4 _60 = _59;
_60.z = payload._m0.z + _38.value.z;
vec4 _61 = _60;
_61.w = payload._m0.w + _38.value.w;
payload._m0 = _61;
11. Root table – Local Root Signature
Cursed mode. In global root signatures, a table costs 1 DWORD, but in local it’s 2, because we are expected to consume a full GPU VA which points to descriptors. Since we work with offsets, we synthesize a fake GPU VA pointer instead in ID3D12DescriptorHeap::GetGPUVirtualAddress(), which we can trivially convert to an offset and then sample the global heap, SM 6.6 style … The GPU VA is faked with the formula (unique_value << 32) + (offset * DescriptorIncrement)
struct CBVData { float4 v; };
ConstantBuffer<CBVData> SBTCBVs[] : register(b4, space15);
struct Payload
{
float4 color;
int index;
};
[shader("miss")]
void RayMiss(inout Payload payload)
{
payload.color += SBTCBVs[payload.index].v;
}
#version 460
#extension GL_EXT_ray_tracing : require
#extension GL_EXT_buffer_reference : require
#extension GL_EXT_nonuniform_qualifier : require
struct _25
{
vec4 _m0;
uint _m1;
};
layout(shaderRecordEXT, std430) buffer SBTBlock
{
uint _m0[5];
uint _m1[6];
uvec2 _m2;
uvec2 _m3;
uvec2 _m4;
uvec2 _m5;
uvec2 _m6;
uvec2 _m7;
uvec2 _m8;
uvec2 _m9;
uvec2 _m10;
} SBT;
layout(set = 5, binding = 0, std140) uniform BindlessCBV
{
vec4 _m0[4096];
} _24[];
layout(push_constant, std430) uniform RootConstants
{
uint _m0;
// ... Global root parameters
} registers;
layout(location = 0) rayPayloadInEXT _25 payload;
vec4 _62;
void main()
{
// Extract offset in descriptor heap from VA.
// The shift amount is configurable.
uint _42 = ((SBT._m9.x >> 5u) + 13u) + payload._m1;
vec4 _61 = _62;
// Force nonuniformEXT here when indexing from SBT
// since it's a bit unclear what dynamically uniform even means for RT.
_61.x = payload._m0.x + _24[nonuniformEXT(_42)]._m0[0u].x;
vec4 _63 = _61;
_63.y = payload._m0.y + _24[nonuniformEXT(_42)]._m0[0u].y;
vec4 _64 = _63;
_64.z = payload._m0.z + _24[nonuniformEXT(_42)]._m0[0u].z;
vec4 _65 = _64;
_65.w = payload._m0.w + _24[nonuniformEXT(_42)]._m0[0u].w;
payload._m0 = _65;
}
So there we have it, at least 11 different ways we can implement CBV in Vulkan from the exact same DXIL input … Oh never mind, make that 12 if we add the -no-legacy-cbuf-layout flag to DXC.
12. CBufferLoad vs LoadLegacy
Non-legacy loads force scalar loads for everything 🙁 It’s also horribly buggy in DXC and drivers, but that’s a story for another time. With legacy model, we only really had to consider loading 128 bits at once with a clean index into float4 array, but now we have a byte-offset based interface. Fortunately, basically no content uses this feature. It’s still opt-in in DXC despite being introduced with SM 6.0.
struct C { uint4 value; };
struct C64 { uint64_t4 value; };
RWStructuredBuffer<uint4> RW : register(u2);
ConstantBuffer<C> CBV : register(b0);
ConstantBuffer<C64> CBV64 : register(b1);
[numthreads(64, 1, 1)]
void main(uint thr : SV_DispatchThreadID, uint wg : SV_GroupID)
{
RW[thr] *= CBV.value;
RW[thr] *= uint4(CBV64.value);
}
#version 460
#extension GL_ARB_gpu_shader_int64 : require
#extension GL_EXT_buffer_reference : require
#extension GL_EXT_nonuniform_qualifier : require
#extension GL_EXT_scalar_block_layout : require
layout(local_size_x = 64, local_size_y = 1, local_size_z = 1) in;
layout(set = 4, binding = 0, std430) buffer SSBO
{
uvec4 _m0[];
} _14[];
// We got descriptor aliasing, no problem!
// We also have actual scalar packing of uniforms :)
layout(set = 5, binding = 0, scalar) uniform BindlessCBV
{
float _m0[16384];
} _21[];
layout(set = 5, binding = 0, scalar) uniform _25_28
{
double _m0[8192];
} _28[];
layout(push_constant, std430) uniform RootConstants
{
uint _m0;
uint _m1;
uint _m2;
uint _m3;
uint _m4;
uint _m5;
uint _m6;
uint _m7;
} registers;
void main()
{
uint _35 = registers._m4 + 2u;
uint _42 = registers._m5 + 1u;
// Please make it stop ...
_14[_35]._m0[gl_GlobalInvocationID.x] = uvec4(
_14[_35]._m0[gl_GlobalInvocationID.x].x *
floatBitsToUint(_21[registers._m5]._m0[0u]),
_14[_35]._m0[gl_GlobalInvocationID.x].y *
floatBitsToUint(_21[registers._m5]._m0[1u]),
_14[_35]._m0[gl_GlobalInvocationID.x].z *
floatBitsToUint(_21[registers._m5]._m0[2u]),
_14[_35]._m0[gl_GlobalInvocationID.x].w *
floatBitsToUint(_21[registers._m5]._m0[3u]));
_14[_35]._m0[gl_GlobalInvocationID.x] = uvec4(
_14[_35]._m0[gl_GlobalInvocationID.x].x *
uint(doubleBitsToUint64(_28[_42]._m0[0u])),
_14[_35]._m0[gl_GlobalInvocationID.x].y *
uint(doubleBitsToUint64(_28[_42]._m0[1u])),
_14[_35]._m0[gl_GlobalInvocationID.x].z *
uint(doubleBitsToUint64(_28[_42]._m0[2u])),
_14[_35]._m0[gl_GlobalInvocationID.x].w *
uint(doubleBitsToUint64(_28[_42]._m0[3u])));
}
Ugh … There isn’t too much we can do though, the DXIL is hardcoded to be scalar here despite all other buffer load interfaces being vectorized to some degree at least.
%5 = call i32 @dx.op.cbufferLoad.i32(i32 58, %dx.types.Handle %3, i32 0, i32 8) ; CBufferLoad(handle,byteOffset,alignment)
// Note the broken alignment, cute. :')
%6 = call i32 @dx.op.cbufferLoad.i32(i32 58, %dx.types.Handle %3, i32 4, i32 8) ; CBufferLoad(handle,byteOffset,alignment)
%7 = call i32 @dx.op.cbufferLoad.i32(i32 58, %dx.types.Handle %3, i32 8, i32 8) ; CBufferLoad(handle,byteOffset,alignment)
%8 = call i32 @dx.op.cbufferLoad.i32(i32 58, %dx.types.Handle %3, i32 12, i32 8) ; CBufferLoad(handle,byteOffset,alignment)
Without robustness, ACO manages to vectorize this garbage at least:
s_buffer_load_dwordx4 s[4:7], s[8:11], 0x0
s_buffer_load_dwordx4 s[8:11], s[12:15], 0x0
s_buffer_load_dwordx4 s[12:15], s[12:15], 0x10
This also holds even for robustness2, but if we start doing dynamically indexing the CBV like this, things collapse into noise since the DXIL mode is doing insane things with the byte offset here.
%5 = shl i32 %4, 4
%6 = call i32 @dx.op.cbufferLoad.i32(i32 58, %dx.types.Handle %3, i32 %5, i32 8) ; CBufferLoad(handle,byteOffset,alignment)
%7 = or i32 %5, 4
%8 = call i32 @dx.op.cbufferLoad.i32(i32 58, %dx.types.Handle %3, i32 %7, i32 8) ; CBufferLoad(handle,byteOffset,alignment)
// ÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆ. I'm out!
%9 = add nsw i32 %7, 4
%10 = call i32 @dx.op.cbufferLoad.i32(i32 58, %dx.types.Handle %3, i32 %9, i32 8) ; CBufferLoad(handle,byteOffset,alignment)
%11 = or i32 %5, 12
%12 = call i32 @dx.op.cbufferLoad.i32(i32 58, %dx.types.Handle %3, i32 %11, i32 8) ; CBufferLoad(handle,byteOffset,alignment)
Sad compiler noises …
Bonus round
Other descriptor types?
At a fundamental level, once we have studied CBVs, there isn’t that much more to cover, except for some key edge cases. The only real differences is how big the descriptors are and the opcodes used with the descriptors, like image_sample, image_load, image_write, etc, but that’s not terribly interesting for this post, so I’ll leave it here.
Raw SRV / UAV vectorization
DXIL raw buffer opcodes are in general quite unfriendly to human readable representations, and it maps very poorly to SSBOs. The robustness rules are also horrible to work with, and making this all work was not fun. After a significant rework, dxil-spirv is somewhat competent now, I think.
The raw buffer interfaces do make sense from an ISA-targeting compiler point-of-view though, I just wish it was a bit more structured for the sake of my sanity … :V
Byte address buffers
ByteAddressBuffers are very annoying. In HLSL, there is only scalar alignment required for a load-store with no way for HLSL shaders to signal intended alignment. There is also a very strange robustness rule. Even for a vector load-store, robustness is per-component at a 16 byte granularity. (why …)
With a simple shader like this, we can do a good job:
RWByteAddressBuffer RW : register(u0);
[numthreads(64, 1, 1)]
void main(uint thr : SV_DispatchThreadID)
{
float4 values = RW.Load<float4>(thr * 16 + 16);
values += 1.0;
RW.Store<float4>(thr * 16 + 16, values);
}
When we attempt to vectorize these loads and stores, we must be able to prove that the SSA expression can be divided by the load-store size, here 16. We can split the addition and compute the result: thr + 1. We then declare an aliased SSBO variant as float4[].
#version 460
layout(local_size_x = 64, local_size_y = 1, local_size_z = 1) in;
layout(set = 0, binding = 0, std430) buffer SSBO
{
uvec4 _m0[];
} _10;
void main()
{
vec4 _29 = uintBitsToFloat(_10._m0[gl_GlobalInvocationID.x + 1u]);
_10._m0[gl_GlobalInvocationID.x + 1u] = uvec4(
floatBitsToUint(_29.x + 1.0),
floatBitsToUint(_29.y + 1.0),
floatBitsToUint(_29.z + 1.0),
floatBitsToUint(_29.w + 1.0));
}
The way we used to implement this was through 4 unrolled scalar load-stores. E.g. if address is changed to something weird like thr * 4 + 20 for the store, we cannot prove vectorization and we fall back into the old and bad code paths.
#version 460
layout(local_size_x = 64, local_size_y = 1, local_size_z = 1) in;
// These are declared with Aliased decorations in SPIR-V.
layout(set = 0, binding = 0, std430) buffer SSBO
{
uint _m0[];
} _9;
layout(set = 0, binding = 0, std430) buffer _12_14
{
uvec4 _m0[];
} _14;
void main()
{
uint _22 = gl_GlobalInvocationID.x << 4u;
uvec4 _30 = _14._m0[gl_GlobalInvocationID.x + 1u];
vec4 _33 = uintBitsToFloat(_30);
uint _46 = gl_GlobalInvocationID.x + 5u;
_9._m0[_46] = floatBitsToUint(_33.x + 1.0);
_9._m0[_46 + 1u] = floatBitsToUint(_33.y + 1.0);
_9._m0[_46 + 2u] = floatBitsToUint(_33.z + 1.0);
_9._m0[_46 + 3u] = floatBitsToUint(_33.w + 1.0);
}
This is a case where robustness2 can matter quite a lot actually … Without robustness, ACO will generate:
v_add_f32_e32 v8, 1.0, v4
v_add_f32_e32 v9, 1.0, v5
v_add_f32_e32 v10, 1.0, v6
v_add_f32_e32 v11, 1.0, v7
buffer_store_dwordx4 v[8:11], v0, s[4:7], 0 offen offset:20
Memory operations on AMD are very flexible w.r.t. alignment fortunately! With robustness2 however, we cannot safely vectorize 🙁
buffer_store_dword v4, v0, s[4:7], 0 offen offset:20
buffer_store_dword v5, v0, s[4:7], 0 offen offset:24
buffer_store_dword v6, v0, s[4:7], 0 offen offset:28
buffer_store_dword v1, v0, s[4:7], 0 offen offset:32
If we emit the vectorized load-store ourselves, we can get vectorized load-store as expected.
The case with float3[] vectorization is very special. With scalar block layout we can implement it, but we need to consider the 16 byte robustness rule. On AMD, we get per-component robustness in hardware, but not on NVIDIA it seems, so for ByteAddressBuffer, float3[] can only conditionally be vectorized. We’re probably going a bit out of spec on Vulkan here I think, but it’s backed up by tests in the vkd3d-proton test suite.
RW.Store<float3>(thr * 12, values.xyz);
ends up as
layout(set = 0, binding = 0, scalar) buffer _12_14
{
uvec3 _m0[];
} _14;
_14._m0[gl_GlobalInvocationID.x] = uvec3(
floatBitsToUint(_41.x + 1.0),
// Individual components might be sliced here. >_<
floatBitsToUint(_41.y + 1.0),
floatBitsToUint(_41.z + 1.0));
buffer_store_dwordx3 v[4:6], v0, s[4:7], 0 offen
Structured buffer
Structured buffers are a bit simpler, but still annoying in practice. While the HLSL declares something like:
struct T { float4 a; float3 b; float c; };
RWStructuredBuffer<T> Buf;
This information is lost in the raw DXIL form except in some reflection metadata that we cannot fully trust. The interface for structured buffers is just:
- Index (usually not constant)
- Offset into structured element (usually constant)
- Load-store size
- Alignment (ignored, DXC emits nonsense here)
Ideally, we would be able to emit the equivalent in SSBO form, but the raw nature of DXIL doesn’t really care anymore about the data types. We can only get effective vectorization for composites like this if the stride aligns with the vector size.
An example here would be:
struct T { float4 a; float3 b; float c; };
RWStructuredBuffer<T> RW : register(u0);
[numthreads(64, 1, 1)]
void main(uint thr : SV_DispatchThreadID)
{
T t = RW[thr];
t.a += 1.0;
t.b += 2.0;
t.c += 3.0;
RW[thr] = t;
}
// Alignment of 4? Sure ... Except we trivially know it's 32 ...
// Told you we cannot trust DXC here! <_<
%3 = call %dx.types.ResRet.f32 @dx.op.rawBufferLoad.f32(i32 139, %dx.types.Handle %1, i32 %2, i32 0, i8 15, i32 4) ; RawBufferLoad(srv,index,elementOffset,mask,alignment)
%8 = call %dx.types.ResRet.f32 @dx.op.rawBufferLoad.f32(i32 139, %dx.types.Handle %1, i32 %2, i32 16, i8 7, i32 4) ; RawBufferLoad(srv,index,elementOffset,mask,alignment)
%12 = call %dx.types.ResRet.f32 @dx.op.rawBufferLoad.f32(i32 139, %dx.types.Handle %1, i32 %2, i32 28, i8 1, i32 4) ; RawBufferLoad(srv,index,elementOffset,mask,alignment)
Since stride is 32, we can vectorize the float4, but not float3.
// float4 load
vec4 _29 = uintBitsToFloat(_14._m0[gl_GlobalInvocationID.x * 2u]);
// float3 load
uint _37 = (gl_GlobalInvocationID.x * 8u) + 4u;
uint _40 = _9._m0[_37];
uint _44 = _9._m0[_37 + 1u];
uint _47 = _9._m0[_37 + 2u];
vec3 _50 = uintBitsToFloat(uvec3(_40, _44, _47));
// float load
uint _58 = _9._m0[(gl_GlobalInvocationID.x * 8u) + 7u];
// float4 store
_14._m0[gl_GlobalInvocationID.x * 2u] = uvec4(
floatBitsToUint(_29.x + 1.0), floatBitsToUint(_29.y + 1.0),
floatBitsToUint(_29.z + 1.0), floatBitsToUint(_29.w + 1.0));
// float3 store
uint _79 = (gl_GlobalInvocationID.x * 8u) + 4u;
_9._m0[_79] = floatBitsToUint(_50.x + 2.0);
_9._m0[_79 + 1u] = floatBitsToUint(_50.y + 2.0);
_9._m0[_79 + 2u] = floatBitsToUint(_50.z + 2.0);
// float store
_9._m0[(gl_GlobalInvocationID.x * 8u) + 7u] =
floatBitsToUint(uintBitsToFloat(_58) + 3.0);
buffer_store_dwordx4 v[12:15], v0, s[4:7], 0 offen
buffer_store_dwordx4 v[4:7], v0, s[4:7], 0 offen offset:16
ACO is being an absolute champ here though, and even with robustness2 it can handle it. I think this happens because it can prove the address increments cannot overflow due to a POT index multiplier.
One saving grace of structured buffers is that it is undefined to straddle an element boundary. This means there is no byte address buffer hell of having to support per-component robustness. We can safely vectorize e.g.
RWStructuredBuffer<float3> Buf;
Root descriptor of ray tracing acceleration structure
If you ever wonder why OpConvertUToAccelerationStructureKHR exists, you can thank yours truly for creating a truly horrible monster.
struct Payload
{
float4 color;
};
RaytracingAccelerationStructure AS_RootDesc : register(t0, space0);
[shader("raygeneration")]
void RayGen()
{
RayDesc ray;
ray.Origin = float3(1, 2, 3);
ray.Direction = float3(0, 0, 1);
ray.TMin = 1.0;
ray.TMax = 4.0;
Payload p;
p.color = float4(1, 2, 3, 4);
TraceRay(AS_RootDesc, RAY_FLAG_NONE, 0, 0, 0, 0, ray, p);
}
#version 460
#extension GL_EXT_ray_tracing : require
#extension GL_EXT_nonuniform_qualifier : require
struct _16
{
vec4 _m0;
};
layout(shaderRecordEXT, std430) buffer SBTBlock
{
uint _m0[5];
uint _m1[6];
uvec2 _m2; // Why hello there. I'm a cursed RTAS.
} SBT;
layout(location = 0) rayPayloadEXT _16 _18;
void main()
{
_18._m0 = vec4(1.0, 2.0, 3.0, 4.0);
traceRayEXT(accelerationStructureEXT(SBT._m2),
0u, 0u, 0u, 0u, 0u,
vec3(1.0, 2.0, 3.0), 1.0,
vec3(0.0, 0.0, 1.0), 4.0, 0);
}
Oh no!
Conclusion
Now you know probably a little too much about descriptors and you can go bug IHVs about this with confidence. D:
There’s a million different ways to do things when it comes to descriptors and D3D12 and Vulkan took completely different approaches here. Developers asked how things work and D3D12 said “… yes”. In response I say ÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆÆ.